
Why Server-Side Data Is Better Than Google Analytics Data

Get helpful updates in your inbox
Why Server-Side Data Is Better Data Than Google Analytics Data
If you work for a publisher or manage a website in general, you’re probably really familiar with Google Analytics. Even if you haven’t used it, you’ve most likely been exposed to it because of its near-universal use across 91.93% of sites on the internet.
While Google Analytics offers a full suite of metrics for free, there are still some limitations within GA’s script-level data, and common misconceptions still exist.
What’s more, the inaccuracy and limitations of the data that can be collected by Google Analytics is especially important to understand for publishers that rely on traffic to generate website revenue.
Today, I’m going to walk you through some of these issues with script-level data and show you why server-side data can potentially help you avoid them altogether. I’ll also highlight what data you can access at the server-side level and how to view this kind of data for free.
What is server-side data on a website?
Server-side data is exactly what the name hints at—data that is collected at or near the server. But what does that actually mean?
To answer that question, first I need to describe how an internet host connects to the internet. It has an Internet Protocol address (IP address). The DNS (Domain Naming System) is the system that helps translate websites like www.example.com into an IP address that a computer can read “216.3.128.12”.
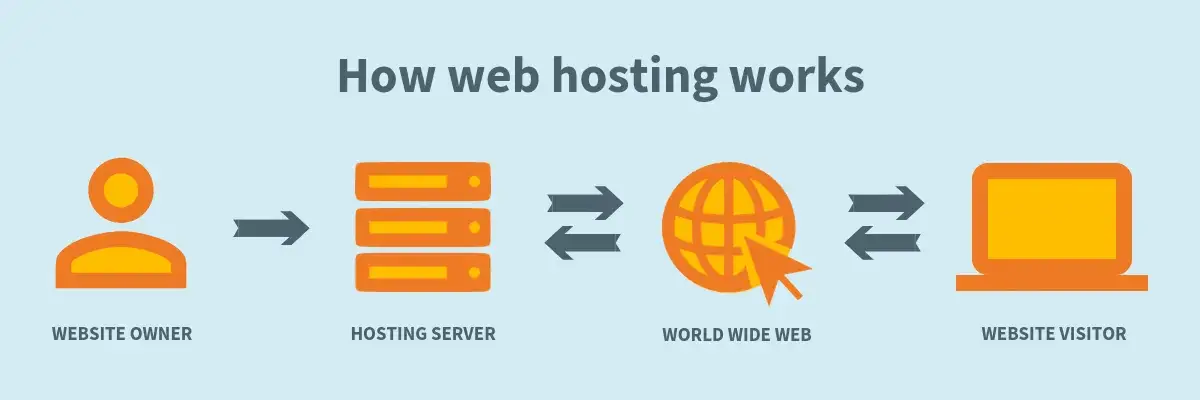
Here’s a breakdown of exactly how it works.
- The web-browser knows you wrote example.com into the address bar.
- Your computer then uses DNS to retrieve the current nameservers for example.com.
- The site’s public nameservers; ns1.example.com and ns2.example.com are retrieved.
- Your computer asks our nameservers for the address record for example.com.
- The site’s public nameservers respond back with the IP address 192.144.142.298
- Your computer sends a request to that IP address along with the page you’re requesting.
- The web server hosting example.com then sends your web-browser the requested page.
All of the above steps happen almost instantaneously.
As a publisher, you most likely pay for a web hosting provider (Bluehost, AWS, Host Gator, GoDaddy, etc). These hosts provide you a server so the series of files, images, and HTML codes that make up your website have a place to be stored online.
Server-side data comes into play when you incorporate a CDN or other technology into your site that sits at the server-level. When a publisher points a website’s nameservers “ns1.example.com and ns2.example.com” to nameservers other than the host, that party becomes a proxy. This can be seen as a relay point, mirror, or channel that the page requests now pass through, like a ghost through a wall.
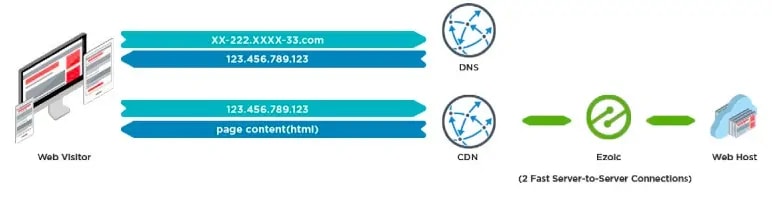
Ezoic’s technology, all CDN’s, and other technologies used by publishers site between the web host and the web visitor requests. This allows traffic to move quickly as requests are made because they don’t require a page to load or be called in order to modify or augment the request.
What is client-side (script data), like Google Analytics?
Client-side data collection is typically accomplished through javascript “tags”. The javascript is typically placed in the header of your site that executes upon page load.
Google Analytics is an example of a script or “tag” that you place on the pages of your site to track visitor behavior.
Note: Many websites now use Google Tag Manager instead of only adding Google Analytics, so instead of this code you would look for the Google Tag manager code.
When a visitor hits a site and the core CSS runs, the third-party Google Analytics tag executes according to the site’s rules, and the visitor data is processed according to the specific specifications or rules on that site (for example, GDPR compliant sites may not collect certain forms of data until cookie consent is given).
Also, there are some issues that exist with how GoogleAnalytics measures bounce rate by default that may provide misleading data to publishers’ in regards to time on site and bounce rate.
What are the benefits of client-side data collection?
Some of the benefits and potential use cases of client-side data are:
- Low cost, simple setup
- You need an easy way to track sales or lead conversions
Some publishers who are just getting started with using data analytics to monitor their sites and like the simplicity of inserting tracking tags into their site’s code, but client-side data has its limitations.
Why is server-side data collection better for web publishers?
Server-side data’s biggest benefits are in the form of accuracy, granularity, and maximizing performance.
The second benefit is added security and data collection ownership. Often, publishers hate the idea of giving Google even more data and insight into their website and would prefer to manage and keep this data private from someone like Google.

The data at the server-side level is able to look more accurately at all the attributes of a user request and can record it in an absolutely granular fashion without needing to execute lots of exterior calls or page-slowdowns to track things like:
- Scroll depth
- Ad viewability
- Engagement time
- Connection type of visitors
- Revenue data
- and more…
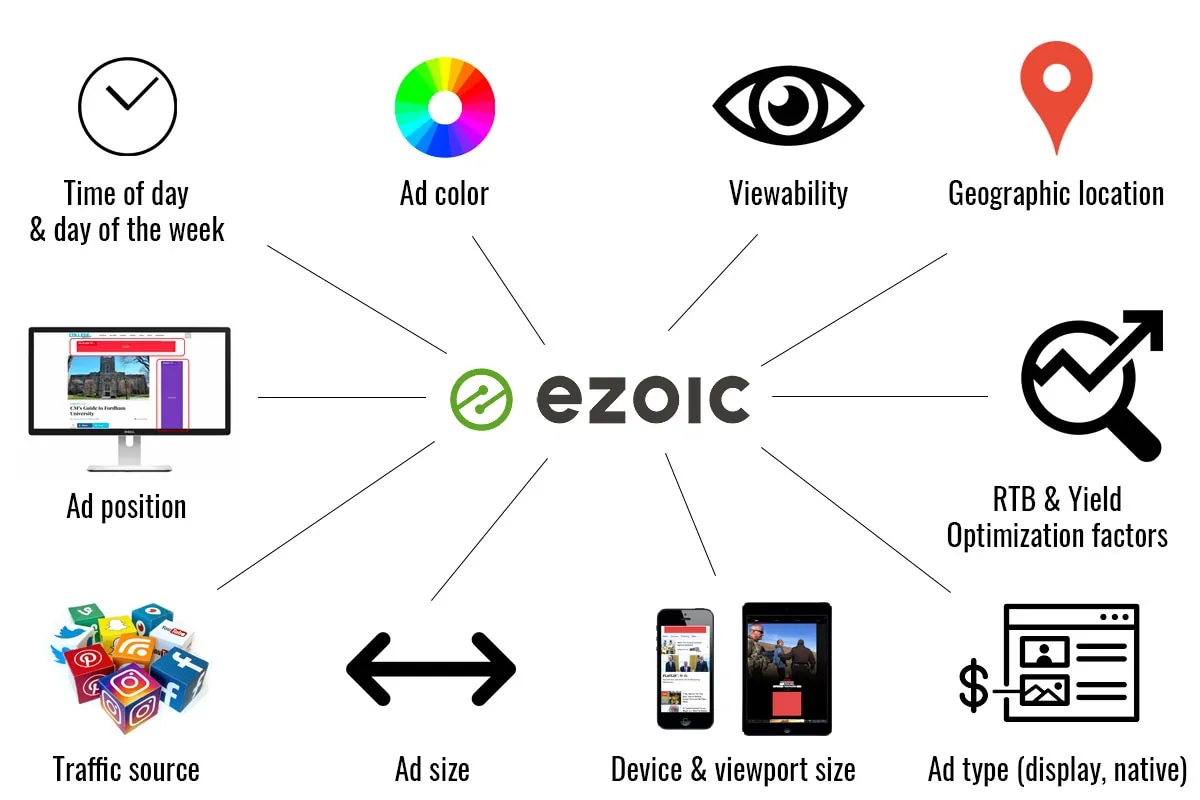
Ezoic’s Big Data Analytics is a great example of tool that provides granular data that is available far-beyond what something like Google Analytics provides.
Additionally, it won’t slow down a page the way a script-level form of analytics will.
A trend towards keeping data away from Google
In the years post-Snowden, Cambridge Analytica, and with privacy legislation like GDPR and CCPA, consumer data privacy is a hot topic.
And with good reason. While 2019 has been the year of the tech giants embracing “privacy for all,” their rocky histories should make people maintain a bit of skepticism of whether these statements are pro-active or rather, just reactive.
Why does this matter? Well, simply put, because to whom your data goes to and what is done with it, matters. Plus, it’s your data—publishers are increasingly opting not to give all their data to Google.
Why does data accuracy matter?
As a publisher, the accuracy of your data analytics might be the line between losing revenue or finding that data point that sparks a new content strategy.
Obviously, you want the latter which can bolster content creation and drive revenue growth.
With Google Analytics, having portions of your site not tagged correctly can contribute to lost data and hamper decisionmaking.
There’s even an in-depth article on 29 different Google Analytics errors and how to fix them. Regardless of how you set up GA, it is still script-level data—meaning it exists only as a piece of javascript on your page.
While Google Tag Manager makes it easier to customize the code with additional tags, Tag Manager still has a bunch of potential errors that can take a lot of time to troubleshoot on your own. Some large businesses even require a specialist to properly set up Google Analytics.
Why does bounce rate accuracy matter?
Bounce rate accuracy matters because if it’s artificially low, you want to address that. If your site has been consistently at a bounce rate in the 60-80% range, and it suddenly drops to the single digits, there is likely something wrong with the Google Analytics tag(s) setup.
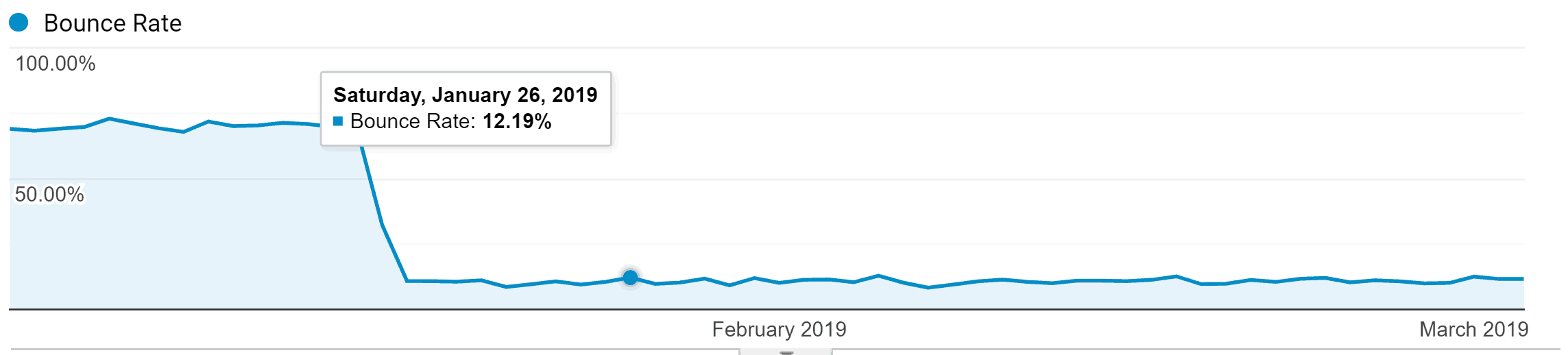
When the bounce rate goes down gradually because of UX changes, you should see increases in things like engagement time, time on site, and scroll depth. You might actually see increases in revenue as well.
What’s an ideal bounce rate?
Bounce rate is relative to every site. You should ask yourself, “What are my landing pages, and what is my experience on these pages?”
Often, publishers will obsess about bounce rates. It could not be a sillier thing to be worried about.
Bounce rates are relative to every publisher. What’s more, how you track it is what you are obsessing over. You are obsessing over something you are electing to measure yourself. That bounce rate is unknown to everyone else.
Even Google Search does not look at the website bounce rate directly. It is often speculated that Google is measuring the relationship between a visitor and the results page and the site that they are clicking on. Meaning, clicking on a result, and then their return to the results page and what they do next is likely the measurement they are using most correlated with bounce rate.
There is no such thing as an ideal bounce rate. The truth is that it varies site to site, but especially by the type of site.

You can see that while a successful retail site might have a bounce rate of 30%, a successful blog might have a bounce rate of 75%. Why the difference?
That’s assuming they are all measuring bounce rate the same way and have the exact same visitors…which they don’t and aren’t!
Is the bounce rate within Google Analytics accurate?
If set up properly, then yes. But every analytics software has its limitations. A frequent support question for users of Ezoic Big Data Analytics is, “Why is my bounce rate different from Google Analytics?”
The quick answer is that unfortunately, Google’s default behavior of tracking is fundamentally flawed and doesn’t accurately reflect active ‘right now’ users on the site.
- Google calculates this ‘right now’ number as the number of unique users that have visited the site in the last 5 minutes.
- Similarly, Ezoic calculates the ‘right now’ number as any user that has ‘some’ activity in the last 5 minutes.
EX: Let’s say a visitor comes to your site and they find a great long-form cornerstone article with a lot of interesting content, and it takes around fifteen minutes to read the entire post. Operating under Google’s definition, they would mark that user inactive after the first 5 minutes.
One of the benefits of Big Data Analytics is that our definition accounts for this visit in real-time. The system knows that the user is being active because the user is scrolling, copying/pasting the content. Because of this difference, publishers will likely see a lower number in Big Data Analytics reports in comparison to Google Analytics.
Big Data Analytics tracks a bounce as when someone doesn’t get what they came for from a website (leaves in less than 30 seconds, doesn’t copy/paste anything, doesn’t scroll to the bottom of the page). Simply leaving after one pageview shouldn’t be considered a “bounce” for most publishers.
Why tying ad revenue to server-side data is very helpful
Tying revenue to analytics is important because it can inform your decisionmaking. It can tell you what you’re doing wrong and what you’re doing right and allow you to adjust accordingly.

If you want to be able to tie your ad revenue data in Google Analytics, it’s going to cost you a whopping $150,000 for Google Analytics 360 (and still won’t allow you to account for any ad demand sources outside of AdX or AdSense).
At such a large price tag, typically only large publishers might find this product helpful for segmenting audiences.
One of the best things about server-side data that can see all sources of revenue on the page, is you can see how revenue is tied to everything. Even when you’re doing it with AdSense, you don’t get the same type of granularity—you get to see how everything affects everything.
- Author metrics
- Categories
- Geos
- Revenue by landing pages
- By device type
- Other ads and their impact on other ad value
- And more
A good example of the type of granularity that I’m talking about is using categories effectively while also having that data tied to revenue.
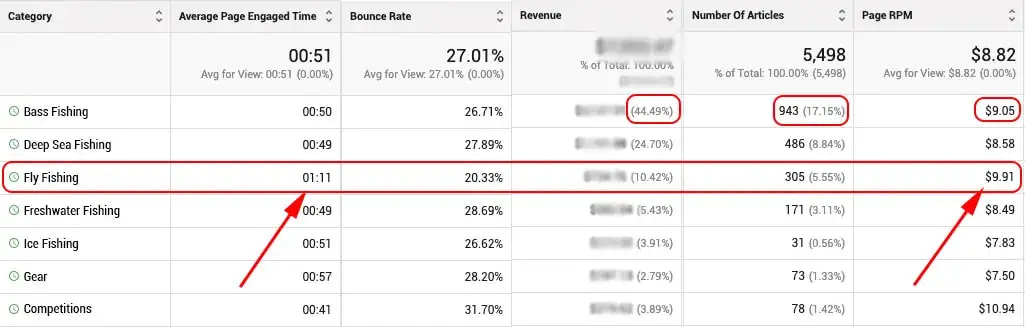
You can see above that “Bass Fishing” accounts for 44.49% of the total site revenue, and also accounts for the highest percentage of articles created as well (17.15%).
But, if you look at the EPMV by article category you see that “Fly Fishing” has the highest EPMV by far from all the categories. What’s more is that the “Average Page Engaged Time” is 1 minute and 11 seconds, a good 20 seconds longer than the majority of the other categories.
This type of categorical data being tied to revenue has the ability to inform your current and future content strategy.
A caveat to the future GA might not be as effective if more websites and browsers start excluding 3rd party scripts, because it’s not local to the site physically collecting the data.
Why you should use server-side data if you can
While there are pros and cons of both server-side and client-side data collection, server-side data provides a more granular and accurate form of analytics for publishers specifically. The majority of server-side data collection will still allow you to incorporate client-side, or script-based data collection, like Google Analytics, on your site anyway if you prefer to use a combination of both.
For publishers who want more granularity in their data, added security, and increased speed—server-side data collection is the best way to go when forced to choose.
Do you have any questions about server-side or client-side data? Let me know in the comments and I’ll try my best to respond.
Allen is a published author and accomplished digital marketer. The author of two separate novels, Allen is a developing marketer with a deep understanding of the online publishing landscape. Allen currently serves as Ezoic's head of content and works directly with publishers and industry partners to bring emerging news and stories to Ezoic publishers.
Featured Content
Checkout this popular and trending content

Ranking In Universal Search Results: Video Is The Secret
See how Flickify can become the ultimate SEO hack for sites missing out on rankings because of a lack of video.
Announcement

Ezoic Edge: The Fastest Way To Load Pages. Period.
Ezoic announces an industry-first edge content delivery network for websites and creators; bringing the fastest pages on the web to Ezoic publishers.
Launch

Ezoic Unveils New Enterprise Program: Empowering Creators to Scale and Succeed
Ezoic recently announced a higher level designed for publishers that have reached that ultimate stage of growth. See what it means for Ezoic users.
Announcement
